All Transformers¶
Here is a list of some of aikit transformers
Text Transformer¶
TextDigitAnonymizer¶
- class
aikit.transformers.text.TextDigitAnonymizer(concat=False)¶Text transformer to anonymize digits.
TextNltkProcessing¶
This is another text pre-processing transformers that does classical text transformations.
- class
aikit.transformers.text.TextNltkProcessing(lower=True, digit_anonymize=True, digit_character='#', remove_non_words=True, remove_stopwords=True, stem=True, concat=False)¶Text transformer using NLKT. It can perform the following steps:
- put the text in lower case
- anonymize digits
- tokenize the words
- remove every words that doesn’t contain any letter
- remove stopwords
- stem the rest
Parameters:
- lower (boolean, default = True) – if True will put the string in lowercase
- digit_anonymize (boolean, default = True) – if True will anonymize digits, replacing them with ‘digit_character’
- digit_character (string, default = '#') – character to use to replace digits
- remove_non_words (boolean, default = True) – if True will remove tokens that are not sequences of letters (aka word)
- remove_stopwords : boolean, default = True
- if True will remove word that are stop words
- stem : boolean, default = True
- if True will perform stemming
Example
>>> texts = ["A stemmer for English operating on the stem cat should identify such strings as cats, catlike, and catty", "A stemming algorithm might also reduce the words fishing, fished, and fisher to the stem fish"] >>> transformer = TextNltkProcessing() >>> transformer.fit_transform(texts) >>> ['stemmer english oper stem cat identifi string cat catlik catti', 'stem algorithm might also reduc word fish fish fisher stem fish']
CountVectorizerWrapper¶
Wrapper around sklearn CountVectorizer.
- class
aikit.transformers.text.CountVectorizerWrapper(analyzer='word', max_df=1.0, min_df=1, ngram_range=1, max_features=None, vocabulary=None, tfidf=False, columns_to_use='all', regex_match=False, desired_output_type='SparseArray', column_prefix='BAG', drop_used_columns=True, drop_unused_columns=True, **other_count_vectorizer_arguments)¶Wrapper around sklearn
CountVectorizerwith additional capabilities:
- can select its columns to keep/drop
- work on more than one columns
- can return a DataFrame
- can add a prefix to the name of columns
Parameters:
- sklearn.CountVectorizer for complete list (See) –
- analyzer (str, default = "word") – type of analyzer (“char”,”word”,”char wb”)
- max_df : float in range [0.0, 1.0] or int, default=1.0
- When building the vocabulary ignore terms that have a document frequency strictly higher than the given threshold (corpus-specific stop words). If float, the parameter represents a proportion of documents, integer absolute counts. This parameter is ignored if vocabulary is not None.
- min_df : float in range [0.0, 1.0] or int, default=1
- When building the vocabulary ignore terms that have a document frequency strictly lower than the given threshold. This value is also called cut-off in the literature. If float, the parameter represents a proportion of documents, integer absolute counts. This parameter is ignored if vocabulary is not None.
- ngram_range : tuple (min_n, max_n) or int (1, ngram_range)
- The lower and upper boundary of the range of n-values for different n-grams to be extracted. All values of n such that min_n <= n <= max_n will be used.
- max_features : int or None, default=None
If not None, build a vocabulary that only consider the top max_features ordered by term frequency across the corpus.
This parameter is ignored if vocabulary is not None.
- vocabulary : Mapping or iterable, optional
- Either a Mapping (e.g., a dict) where keys are terms and values are indices in the feature matrix, or an iterable over terms. If not given, a vocabulary is determined from the input documents. Indices in the mapping should not be repeated and should not have any gap between 0 and the largest index.
- tfidf : boolean, default = False
- if True will use a TfIdfVectorizer, otherwise regular CountVectorizer
- columns_to_use : None or list of string
- this parameter will allow the wrapped transformer to select its columns
- regex_match : boolean, default = False
- if True will use a regex to match columns otherwise exact match
- column_prefix : str or None, default = “BAG”
- prefix of the column
- drop_used_columns : boolean, default=True
- what to do with the ORIGINAL columns that were transformed. If False, will keep them in the result (un-transformed) If True, only the transformed columns are in the result
- drop_unused_columns: boolean, default=True
- what to do with the column that were not used. if False, will drop them if True, will keep them in the result
- desired_output_type : None or DataType
- specify the desired output type of transformer, a conversion will be made if necesary
Word2VecVectorizer¶
This model does Continuous bag of word, meaning that it will fit a Word2Vec model and then average the word vectors of each text.
- class
aikit.transformers.text.Word2VecVectorizer(size=100, window=5, min_count=5, text_preprocess='default', same_embedding_all_columns=True, use_fast_text=False, random_state=None, other_params=None, columns_to_use='all', desired_output_type='DataFrame', regex_match=False, drop_used_columns=True, drop_unused_columns=True)¶
- Word2Vec vectorizer, this model does an average of the embedding of each word :
- size : int, default = 100
- the size of the embedding
- window : int, default = 5
- the size of the training window of the word2vec model
- text_preprocess: string, default = ‘default’
- type of text preprocessing to use, possible choices are : * ‘default’ : TextDefaultProcessing : put everything in lower case and remove some punctuation * ‘digit’ : TextDigitAnonymizer : anonymize digits * ‘nltk’ : TextNltkProcessing : lower, stemming, remove stopwords, … * None : do nothing
- same_embedding_all_columns : boolean, default = True
- if True will fit ONE embedding for ALL the text columns, otherwise will fit one word2vec PER text column
- use_fast_text : boolean, default = False
- if True will use fasttext instead of gensim
- random_state : None or int
- state of random generator
- other_params : dict or None, default = None
- columns_to_use : list,
- columns to encode
- desired_output_type : data type, default = DataFrame
- desired output type
- drop_used_columns : boolean, default=True
- what to do with the ORIGINAL columns that were transformed. If False, will keep them in the result (un-transformed) If True, only the transformed columns are in the result
- drop_unused_columns: boolean, default=True
- what to do with the column that were not used. if False, will drop them if True, will keep them in the result
Char2VecVectorizer¶
This model is the equivalent of a “Bag of N-gram” characters but using embedding. It is fitting embedding for sequence of caracters and then average all those embeddings.
- class
aikit.transformers.text.Char2VecVectorizer(size=100, window=5, ngram=3, text_preprocess='default', same_embedding_all_columns=True, use_fast_text=False, random_state=None, other_params=None, columns_to_use='all', desired_output_type='DataFrame', regex_match=False, drop_used_columns=True, drop_unused_columns=True)¶
- Char2Vec vectorizer, this model does an average of the embedding of each ngram :
- size : int, default = 50
- the size of the embedding
- window : int, default = 5
- the size of the training window of the word2vec model
- ngram : int, default = 3
- the size of the ngram on which we will fit embedding
- text_preprocess: string, default = ‘default’
- type of text preprocessing to use, possible choices are : * ‘default’ : TextDefaultProcessing : put everything in lower case and remove some punctuation * ‘digit’ : TextDigitAnonymizer : anonymize digits * ‘nltk’ : TextNltkProcessing : lower, stemming, remove stopwords, … * None : do nothing
- same_embedding_all_columns : boolean, default = True
- if True will fit ONE embedding for ALL the text column, otherwise will fit one word2vec PER text column
- random_state : None or int
- state of random generator
- other_params : dict or None, default = None
- columns_to_use : list,
- columns to encode
- desired_output_type : data type, default = DataFrame
- desired output type
- drop_used_columns : boolean, default=True
- what to do with the ORIGINAL columns that were transformed. If False, will keep them in the result (un-transformed) If True, only the transformed columns are in the result
- drop_unused_columns: boolean, default=True
- what to do with the column that were not used. if False, will drop them if True, will keep them in the result
Dimension Reduction¶
TruncatedSVDWrapper¶
Wrapper around sklearn TruncatedSVD.
- class
aikit.transformers.base.TruncatedSVDWrapper(n_components=2, columns_to_use='all', regex_match=False, random_state=None, drop_used_columns=True, drop_unused_columns=True)¶Wrapper around sklearn
TruncatedSVDwith additional capabilities:
- can select its columns to keep/drop
- work on more than one columns
- can return a DataFrame
- can add a prefix to the name of columns
n_componentscan be a float, if that is the case it is considered to be a percentage of the total number of columns.
KMeansTransformer¶
This transformers does a KMeans clustering and uses the cluster to generate new features (based on the distance between each cluster). Remark : for the ‘probability’ result_type, since KMeans isn’t a probabilistic model the probability is computed using an heuristic.
- class
aikit.transformers.base.KMeansTransformer(n_clusters=10, result_type='probability', temperature=1, scale_input=True, random_state=None, columns_to_use='all', regex_match=False, desired_output_type='DataFrame', drop_used_columns=True, drop_unused_columns=True, kmeans_other_params=None)¶Transformer that apply a KMeans and output distance from cluster center
Parameters:
- n_clusters (int, default = 10) – the number of clusters
- result_type (str, default = 'probability') –
determines what to output. Possible choices are
- ’probability’ : number between 0 and 1 with ‘probability’ to be in a given cluster
- ’distance’ : distance to each center
- ’inv_distance’ : inverse of the distance to each cluster
- ’log_disantce’ : logarithm of distance to each cluster
- ’cluster’ : 0 if in cluster, 1 otherwise
- temperature (float, default = 1) – used to shift probability :unormalized proba = proba ^ temperature
- scale_input (boolean, default = True) – if True the input will be scaled using StandardScaler before applying KMeans
- random_state (int or None, default = None) – the initial random_state of KMeans
- columns_to_use (list of str) – the columns to use
- regex_match (boolean, default = False) – if True use regex to match columns
- drop_used_columns (boolean, default=True) – what to do with the ORIGINAL columns that were transformed. If False, will keep them in the result (un-transformed) If True, only the transformed columns are in the result
- drop_unused_columns (boolean, default=True) – what to do with the column that were not used. if False, will drop them if True, will keep them in the result
- desired_output_type (DataType) – the type of result
Feature Selection¶
FeaturesSelectorRegressor¶
This transformer will perform feature selection. Different strategies are available:
- “default” : uses sklearn default selection, using correlation between target and variable
- “linear” : uses absolute value of scaled parameters of a linear regression between target and variables
- “forest” : uses
feature_importancesof a RandomForest between target and variables
- class
aikit.transformers.base.FeaturesSelectorRegressor(n_components=0.5, selector_type='forest', component_selection='number', model_params=None, columns_to_use='all', regex_match=False, drop_used_columns=True, drop_unused_columns=True)¶Features Selection based on RandomForest, LinearModel or Correlation.
Parameters:
- n_components (int or float, default = 0.5) – number of component to keep, if float interpreted as a percentage of X size
- component_selection (str, default = "number") – if “number” : will select the first ‘n_components’ features if “elbow” : will use a tweaked ‘elbow’ rule to select the number of features
- selector_type (string, default = 'forest') – ‘default’ : using sklearn f_regression/f_classification ‘forest’ : using RandomForest features importances ‘linear’ : using Ridge/LogisticRegression coefficient
- random_state (int, default = None) –
- model_params – Model hyper parameters
FeaturesSelectorClassifier¶
Exactly as aikit.transformers.base.FeaturesSelectorRegressor but for classification.
- class
aikit.transformers.base.FeaturesSelectorClassifier(n_components=0.5, selector_type='forest', component_selection='number', random_state=None, model_params=None, columns_to_use='all', regex_match=False, drop_used_columns=True, drop_unused_columns=True)¶Features Selection based on RandomForest, LinearModel or Correlation.
Parameters:
- n_components (int or float, default = 0.5) – number of component to keep, if float interpreted as a percentage of X size
- component_selection (str, default = "number") – if “number” : will select the first ‘n_components’ features if “elbow” : will use a tweaked ‘elbow’ rule to select the number of features
- selector_type (string, default = 'forest') – ‘default’ : using sklearn f_regression/f_classification ‘forest’ : using RandomForest features importances ‘linear’ : using Ridge/LogisticRegression coefficient
- random_state (int, default = None) –
- model_params – Model hyper parameters
Missing Value Imputation¶
NumImputer¶
Numerical value imputer for numerical features.
- class
aikit.transformers.base.NumImputer(strategy='mean', add_is_null=True, fix_value=0, allow_unseen_null=True, columns_to_use='all', regex_match=False, drop_used_columns=True, drop_unused_columns=True)¶Missing value imputer for numerical features.
Parameters:
- strategy (str, default = 'mean') – how to fill missing value, possibilities (‘mean’, ‘fix’ or ‘median’)
- add_is_null (boolean, default = True) – if this is True of ‘is_null’ columns will be added to the result
- fix_value (float, default = 0) – the fix value to use if needed
- allow_unseen_null (boolean, default = True) – if not True an error will be generated on testing data if a column has missing value in test but didn’t have one in train
- columns_to_use (list of str or None) – the columns to use
- drop_used_columns (boolean, default=True) – what to do with the ORIGINAL columns that were transformed. If False, will keep them in the result (un-transformed) If True, only the transformed columns are in the result
- drop_unused_columns (boolean, default=True) – what to do with the column that were not used. if False, will drop them if True, will keep them in the result
- regex_match (boolean, default = False) – if True, use regex to match columns
Categories Encoding¶
NumericalEncoder¶
This is a transformer to encode categorical variable into numerical values.
The transformer handle two types of encoding:
- ‘dummy’ : dummy encoding (aka : one-hot-encoding)
- ‘num’ : simple numerical encoding where each modality is transformed into a number
The transformer includes also other capabilities to simplify encoding pipeline:
- merging of modalities with too few observations to prevent huge result dimension and overfitting,
- treating
Nonehas a special modality if manyNoneare present,- if the columns are not specified, guess the columns to encode based on their type
- class
aikit.transformers.categories.NumericalEncoder(columns_to_use='CAT', min_modalities_number=20, max_modalities_number=100, max_cum_proba=0.95, min_nb_observations=10, max_na_percentage=0.05, encoding_type='dummy', regex_match=False, desired_output_type='DataFrame', drop_used_columns=True, drop_unused_columns=False)¶Numerical Encoder of categorical variables
Parameters:
- columns_to_use (list of str) – the columns to use
- min_modalities_number (int, default = 20) – if less that ‘min_modalities_number’ modalities no modalities will be filtered
- max_modalities_number (int, default = 100,) – the number of modalities kept will never be more than ‘max_modalities_number’
- max_cum_proba (float, default = 0.95) – if modalities should be filtered, first filter applied is removing modalities that account for less than 1-‘max_cum_proba’
- min_nb_observations (int, default = 10) – if modalities should be filtered, modalities with less thant ‘min_nb_observations’ observations will be removed
- max_na_percentage (float, default = 0.05) – if more than ‘max_na_percentage’ percentage of missing value, None will be treated as a special modality named ‘__null__’ otherwise, will just put -1 (for encoding_type == ‘num’) or 0 everywhere (for encoding_type == ‘dummy’)
- encoding_type ('dummy' or 'num', default = 'dummy') – type of encoding between a numerical encoding and a dummy encoding
- regex_match (boolean, default = False) – if True use regex to match columns
- desired_output_type (DataType) – the type of result
- drop_used_columns (boolean, default=True) – what to do with the ORIGINAL columns that were transformed. If False, will keep them in the result (un-transformed) If True, only the transformed columns are in the result
- drop_unused_columns (boolean, default=True) – what to do with the column that were not used. if False, will drop them if True, will keep them in the result
CategoricalEncoder¶
This is a wrapper around module:categorical_encoder package.
- class
aikit.transformers.categories.CategoricalEncoder(columns_to_use='CAT', encoding_type='dummy', basen_base=2, hashing_n_components=10, regex_match=False, desired_output_type='DataFrame', drop_used_columns=True, drop_unused_columns=False)¶Wrapper around categorical encoder package encoder
Parameters:
- columns_to_encode (None or list of str) – the columns to encode (if None will guess)
- encoding_type (str, default = 'dummy') –
- the type of encoding, possible choices :
- dummy
- binary
- basen
- hashing
- basen_base (int, default = 2) – the base when using encoding_type == ‘basen’
- hashing_n_components (int, default = 10) – the size of hashing when using encoding_type == ‘hashing’
- columns_to_use (list of str or None) – the columns to use for that encoder
- regex_match (boolean) – if True will use regex to match columns
- desired_output_type (list of DataType) – the type of output wanted
- drop_used_columns (boolean, default=True) – what to do with the ORIGINAL columns that were transformed. If False, will keep them in the result (un-transformed) If True, only the transformed columns are in the result
- drop_unused_columns (boolean, default=True) – what to do with the column that were not used. if False, will drop them if True, will keep them in the result
TargetEncoderRegressor¶
This transformer also handles categorical encoding but uses the target to do that. The idea is to encode each modality into the mean of the target on the given modality. To do that correctly special care should be taken to prevent leakage (and overfitting).
The following techniques can be used to limit the issue :
- use of an inner cross validation loop (so an observation in a given fold will be encoded using the average of the target computed on other folds)
- noise can be added to encoded result
- a prior corresponding to the global mean is apply, the more observations in a given modality the less weight the prior has
- class
aikit.transformers.target.TargetEncoderRegressor(columns_to_use='CAT', max_na_percentage=0.05, smoothing_min=1, smoothing_value=10, noise_level=None, cv=10, random_state=None, regex_match=False, desired_output_type='DataFrame', drop_used_columns=True, drop_unused_columns=False)¶Class to encode categorical value using the target
Parameters:
- max_na_percentage (float, default = 0.05) – if more than ‘max_na_percentage’ None within a column, None will be treated as a special modality, otherwise it will default to the global aggregat
- smoothing_min (float, default = 1) – handle the prior weight, see formula bellow
- smoothing_value (float, default = 10) – handle the speed with which the prior is forgotten (see formula bellow)
- noise_level (float or None, default = None) – degree of noise to add within the fit_transform
- cv (int, None, or CV object, default = 10) – the cv to use within fit_transform
Those parameters handles the prior weight, WEIGHT = 1/[1 + EXP( - (nb - smoothing_min) / smoothing_value ) ] where ‘nb’ is the number of observations of the corresponding modality
The precautions explained above causes the transformer to have a different behavior when doing:
fitthentransformfit_transform
When doing fit then transform, no noise is added during the transformation and the fit save the global average of the target.
This is what you’d typically want to do when fitting on a training set and then applying the transformation on a testing set.
When doing fit_transform, noise can be added to the result (if noise_level != 0) and the target aggregats are computed fold by fold.
To understand better here is what append when fit is called :
- variables to encode are guessed (if not specified)
- global average per modality is computed
- global average (for all dataset) is computed (to use as prior)
- global standard deviation of target is computed (used to set noise level)
- for each variable and each modality compute the encoded value using the global aggregat and the modality aggregat (weighted by a function of the number of observations for that modality)
Now here is what append when transform is called :
- for each variable and each modality retrieve the corresponding value and use that numerical feature
Now when doing a fit_transform :
- call
fitto save everything needed to later be able to transform unseen data- do a cross validation and for each fold compute aggregat and the remaining fold
- use that value to encode the modality
- add noise to the result : proportional to
noise_level * global standard deviation
TargetEncoderClassifier¶
This transformer handles categorical encoding and uses the target value to do that.
It is the same idea as TargetEncoderRegressor but for classification problems.
Instead of computing the average of the target, the probability of each target classes is used.
The same techniques are used to prevent leakage.
- class
aikit.transformers.target.TargetEncoderClassifier(columns_to_use='CAT', max_na_percentage=0.05, smoothing_min=1, smoothing_value=10, noise_level=None, cv=10, random_state=None, regex_match=False, desired_output_type='DataFrame', drop_used_columns=True, drop_unused_columns=False)¶Class to encode categorical value using the target
Parameters:
- max_na_percentage (float, default = 0.05) – if more than ‘max_na_percentage’ None within a column, None will be treated as a special modality, otherwise it will default to the global aggregat
- smoothing_min (float, default = 1) – handle the prior weight, see formula bellow
- smoothing_value (float, default = 10) – handle the speed with which the prior is forgotten (see formula bellow)
- noise_level (float or None, default = None) – degree of noise to add within the fit_transform
- cv (int, None, or CV object, default = 10) – the cv to use within fit_transform
Those parameters handles the prior weight, WEIGHT = 1/[1 + EXP( - (nb - smoothing_min) / smoothing_value ) ] where ‘nb’ is the number of observations of the corresponding modality
Other Target Encoder¶
Any new target encoder can easily be created using the same technique.
The new target encoder class must inherit from _AbstractTargetEncoder,
then the aggregating_function can be overloaded to compute the needed aggregat.
The _get_output_column_name can also be overloaded to specify feature names.
Scaling¶
CdfScaler¶
This transformer is used to re-scale feature, the re-scaling is non linear. The idea is to fit a cdf for each feature and use it to re-scale the feature to be either a uniform distribution or a gaussian distribution.
- class
aikit.transformers.base.CdfScaler(distribution='auto-kernel', output_distribution='uniform', copy=True, verbose=False, sampling_number=1000, random_state=None, columns_to_use='all', regex_match=False, drop_used_columns=True, drop_unused_columns=True, desired_output_type=None)¶Scaler based on the distribution
- Each variable is scaled according to its law. The law can be approximated using :
- parametric law : distribution = “normal”, “gamma”, “beta”
- kernel approximation : distribution = “kernel”
- rank approximation : “rank”
- if distribution = “none” : no distribution is learned and no transformation is applied (useful to not transform some of the variables)
- if distribution = “auto-kernel” : automatic guessing on which column to use a kernel (columns whith less than 5 differents values are un-touched)
- if distribution = “auto-param” : automatic guessing on which column to use a parametric distribution (columns with less than 5 differents valuee are un-touched)
for other columns choice among “normal”, “gamma” and “beta” law based on values taken
- After the law is learn, the result is transformed into :
- a uniform distribution (output_distribution = ‘uniform’)
- a gaussian distribution (output_distribution = ‘normal’)
Parameters:
- distribution (str or list of str, default = "auto-kernel") – the distribution to use for each variable, if only one string the same transformation is applied everything where
- output_distribution (str, default = "uniform") – type of output, either “uniform” or “normal”
- copy (boolean, default = True) – if True wil copy the data then modify it
- verbose (boolean, default = True) – set the verbosity level
- sampling_number (int or None, default = 1000) – if set subsample of size ‘sampling_number’ will be drawn to estimate kernel densities
- random_state (int or None) – state of the random generator
- columns_to_use (list of str) – the columns to use
- regex_match (boolean, default = False) – if True use regex to match columns
- drop_used_columns (boolean, default=True) – what to do with the ORIGINAL columns that were transformed. If False, will keep them in the result (un-transformed) If True, only the transformed columns are in the result
- drop_unused_columns (boolean, default=True) – what to do with the column that were not used. if False, will drop them if True, will keep them in the result
- desired_output_type (DataType) – the type of result
Target Transformation¶
BoxCoxTargetTransformer¶
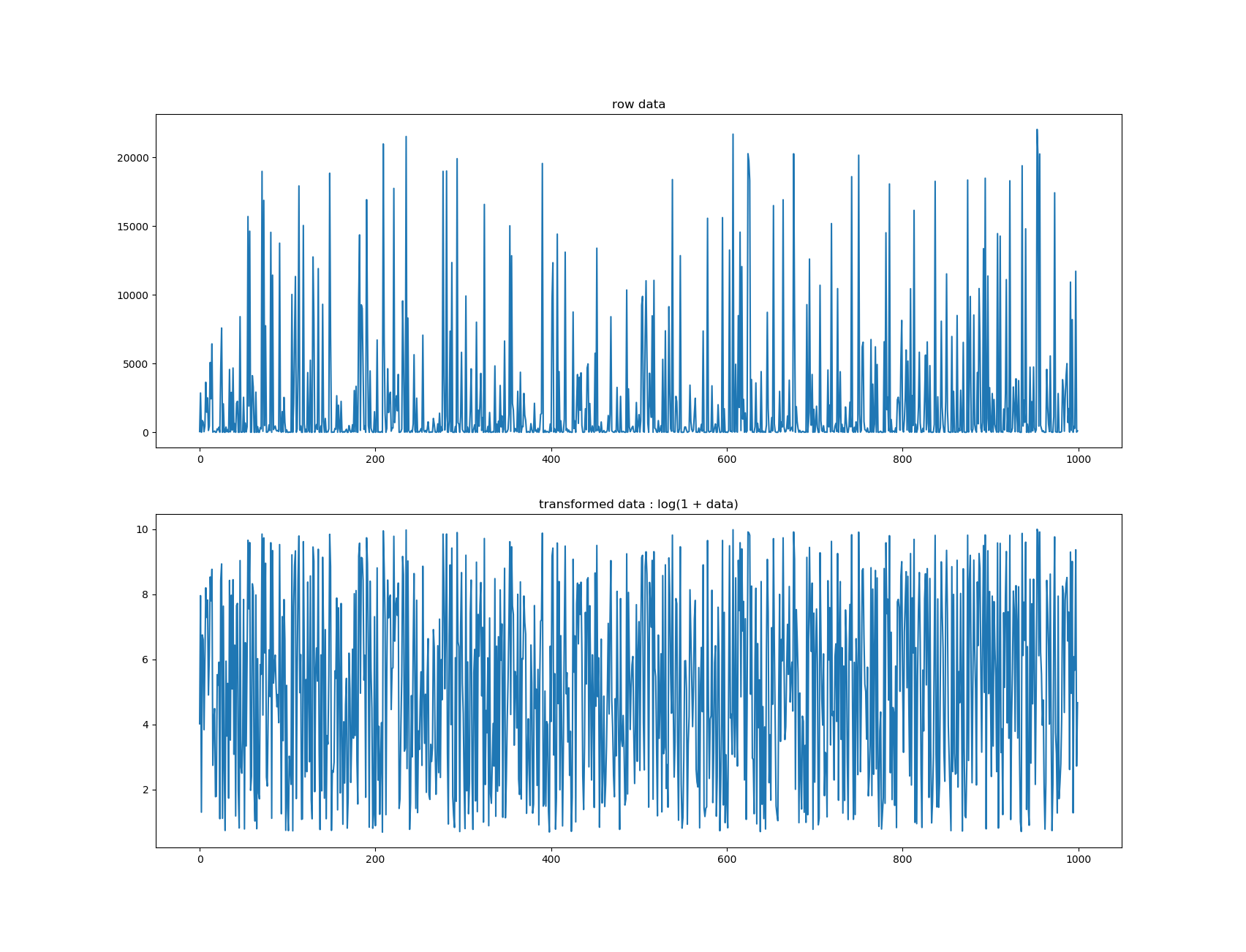
This transformer is a regression model that modify that target by applying it a boxcox transformation. The target can be positive or negative. This transformation is useful to flatten the distribution of the target which can help underlying model (especially those who are not robust to outliers).
Remark : It is important to note that when predicting the inverse transformation will be applied. If what is important to you is the error on the logarithm of the error you should:
- directly transform you target before anything
- use a customized scorer
- class
aikit.transformers.base.BoxCoxTargetTransformer(model, ll=0)¶BoxCoxTargetTransformer, it is used to fit the underlying model on a transformation of the target
- the model does the following :
- transform target using ‘target_transform’
- fit the underlying model on transformation
- when prediction, apply ‘inverse_transformation’ to result
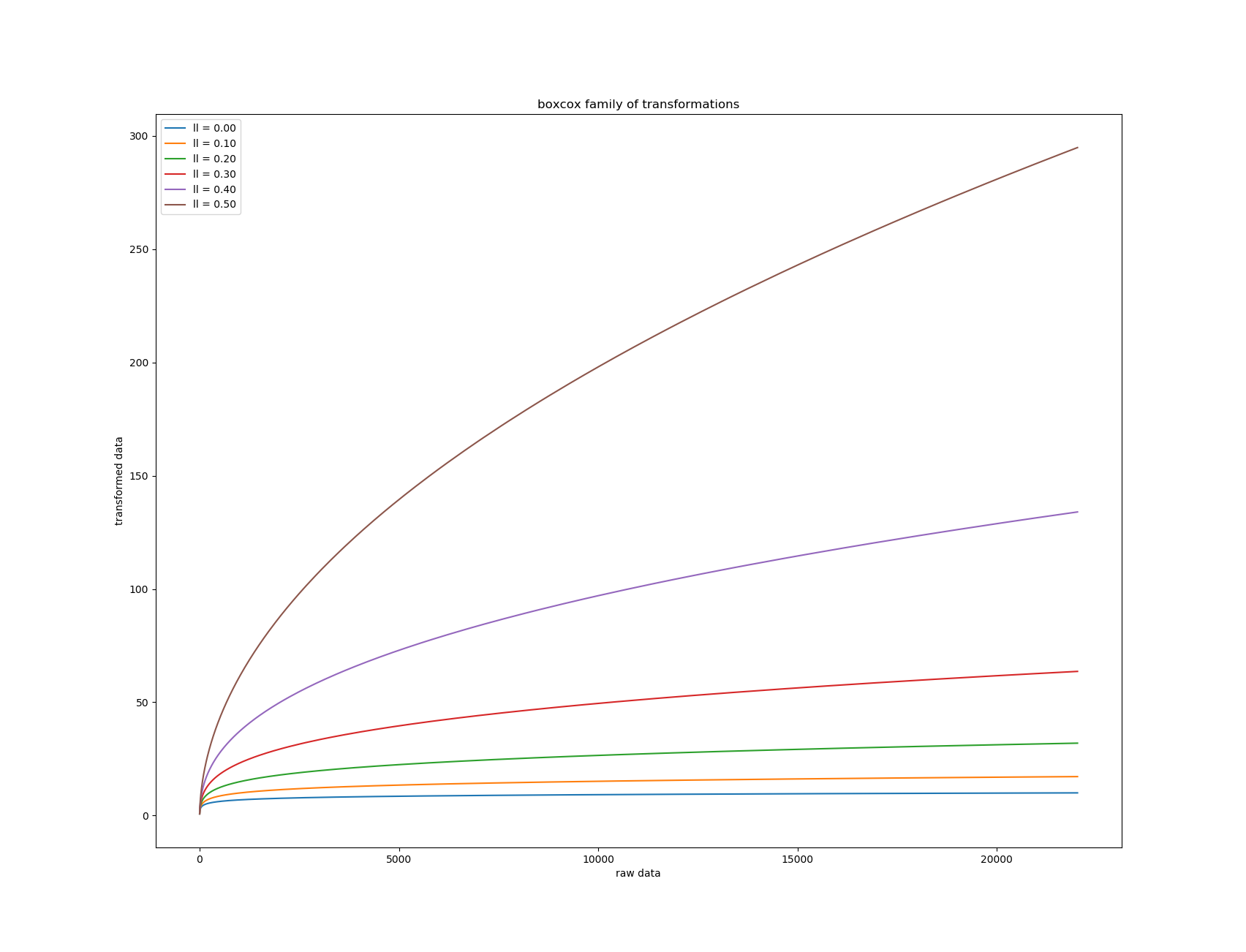
Here the transformation is in the ‘box-cox’ family.
- ll = 0 means this transformation : sign(x) * log(1 + abs(x))
- ll > 0 sign(x) * exp( log( 1 + ll * abs(xx) ) / ll - 1 )
Parameters:
- model (sklearn like model) – the model to use
- ll (float, default = 0) – the boxcox parameter
Example of transformation using ll = 0:
When ll increases the flattenning effect diminishes :